AI Hot Takes From A Platform Engineer / SRE
A blip appeared on my phone while I was on the treadmill last week, it was yet another LinkedIn post talking about the wonderful value AI has brought upon us. Day after day, anywhere I look, I have to sit through opinions that are exuberantly optimistic. Yet all examples given are always tiny tools, and I have yet to see a real-world example of agentic usage in production critical systems that hasn’t gone wrong, or at best underperforming.
Don’t get me wrong, I derive extensive value from the use of AI and I do enjoy using coding agents for prototypes, tools and debugging. But I sense a disconnect between what the AI evangelists say, and what I experience first hand. We need some pragmatic counterbalance to ground some of the marketing fluff in reality.
So here are some of my hot takes on the current state of AI, March 2026.
# Hot Take 1: Anything In Public Can Be Learnt If You Want To
With AI Big Tech currently heavily subsidising our freely accessible usage of sequence guessing generators, everyone is able to to skip right past the data organisation and accessibility phases of organising the world’s information and making it universally accessible and useful to ourselves. The chatbots are now capable enough to do JIT search MCP, so we can worry less about recency of information.
During my bus rides, I’d use Gemini Deep Research to do a deep dive on stuff like “Latest Trends in Incident Management, Anchored to March 2026” to keep up with the latest industry practices. This would provide me with adequate entertainment on my 22km commute, which is otherwise an inexplicably 1h40m long, excruciating bus journey home. If anything in the generated article feels incredulous, I would pull out my dusty Google-fu and fact check the information.
Although… I can no longer tell if LLMs are becoming more accurate, or I’m fact checking less, or the LLMs are hallucinating more convincingly now.
Some of my teammates have asked how I know so much about everything. The secret is to make up custom content to read so I can learn whatever I want. Did you know that ZZ plants remove access water by crying out of their leaves via a process called guttation? I became a ZZ plant horticulturist for a very brief 5 minutes one day.
Another great example of learning via AI is when I uploaded the Japanese user manual for my Casio Oceanus into NotebookLM and was able to ask about how to fix the misaligned minute hand in English. One of my team members also became an expert on his own personal health insurance details by uploading the insurance policy PDF to AI. There are no longer any excuses to not know everything in at least a half-assed manner while having the option to go transiently deep.

We have in our hands the ultimate tool, a Library of BabelBabble, to teach us whatever we want.
# Hot Take 2: Because Of AI, It’s Now Okay To Ignore AI Trends
The new paradigm of learning presented in HT1 above means that I really don’t need to adopt or adapt to the latest AI craze. Before AI, SWEs have often lamented that the software industry is in constant flux, and it’s exhausting to keep up with the latest technologies. This has now been taken to the extreme as coding agents are enabling anyone to just build an Open<buzzword>.
New JS framework every 2 months? How about new AI-slopped tools every 2 hours?
Code quality and review standards? How about a vibe coded LLM cron job that was never code reviewed?
RAM shortage? How about having all commandline tools default to running a JS runtime on everyone’s machines?
The sheer amount of AI generated rebranding of remakes of reinvented concepts is impossible to keep up with.
Recently I commented about agentic orchestration being non-deterministic workflows that would hallucinate even on data fetched via RAG. The response I got wasn’t focused on the remark about stochasticism, but instead was about how my knowledge was outdated because RAG has been deprecated. This puzzled me because I thought RAG was about retrieving data from different static/dynamic sources not within the trained model to give a more relevant output. You know, to Retrieve data for Augmenting Generated text. But allegedly that definition had changed, and it solely means retrieval of static data from a vector database now.
RAG Nigoki is now JIT-Search-Grounding, or DeepRAG, or whatever newly coined terminology to describe retrieving live or dynamic data. This is just one example of a few scenarios where I’ve found people in this industry inventing new words to claim naming rights to a subset of otherwise straightforward concepts. These are the same people who, when explaining to laymen, seem incapable of conveying ideas and prefer authority through obfuscation.

Concepts and application experience don’t seem to matter, knowledge of the latest buzzwords defines one’s engineering expertise. In this new wild west gold rush that is 1000x Blockchain frenzy, everyone wants to flag-plant their name on a new buzzword.
However, my belief is that we can all tune out the noise, ignore the AI hype from everyone, and just focus on delivering on our core business OKRs.
Here’s why I think so:
- Back in 2023, I had found some success in writing software by copying the LLM outputs back into the prompts to force it to continue thinking through the execution steps. Shortly after, this process was automated away in both ChatGPT and Gemini. That skillset was no longer needed.
- Later on, people started trying to expose APIs to LLMs by having bootstrapped clients listen to generated text for explicit tool calls. There was a whole handful of weeks where everyone was talking about having to learn how to integrate execution with LLM instructions. Then Anthropic released MCP. That tooling protocol skill set was no longer needed.
- Almost immediately after the coining of vibe coding, autonomous coding agents were launched. Once again, the industry was in a mad rush to learn how to write product specifications to ground the agents, and having to sandbox the agents with containers or VMs or role permissions. Then the coding agent companies automated all of these away. Write specifications? That’s so February 2026. Use a cheap LLM to interview yourself instead to generate the
SPEC.md, leet vibecoders don’t write their specifications like normies now.
We seem to have forgotten that AI is an enabling tool, not the goal. Just think about the sheer amount of engineering waste going on in all the AI-consuming companies going through these cycles learning all the disposable buzzword workflows.
Do companies still remember that their core business is to delight users in exchange for money?

Everything you know about AI workflows now will be redundant in no time, while the AI companies are brainwashing their model consumers into willing guinea pigs for their latest NewMethod™. You could have spent that time using vanilla AI assistance in your own way to hit your actual OKRs instead of sweating the details of AI adoption. Step away for 6 months, then ask your favourite LLM, “So what’d I miss?” You’ll be back at the forefront like everyone else without wasting time on disposable knowledge.
Outputs are valued now, not the process. The outcome (AI workflows must be in everything) has already been decided, the method of execution does not matter. If the outcome is not delivered, blame the process and blame the skill.
Vibe coded software leading to more security vulnerabilities? It’s the engineer’s fault for not putting in proper guardrails. Coding agents inventing new specifications not documented in SPEC.md or AGENTS.md? It’s the engineer’s fault for not writing better MD files. Agents going rogue and executing tasks it’s not supposed to? It’s the engineer’s fault for not keeping a negative constraint MD file which may as well be asking to prove a negative.
When an AI integration project works out, the value of AI is vindicated. If the project fails to deliver, engineers have an AI skill issue. It is always the engineers’ fault for not rethinking their SDLC workflows to rein in the hallucinations. Surely they must have been shoehorning AI into everyday tasks and not reinventing Agentic Experience (AX™). Adapt or get left behind. May the best context engineer win.
Or maybe, the DevEx of agentic coding just sucks.
I, too, enjoy slopping away on Claude Code making nifty little apps that convert my file formats and parse my bank statements. But trying to go beyond a small scope quickly reduces the process into a painful juggling of Markdown files and anger management.
- I enjoy writing documentation, but writing transient Markdown files is pure agony.
- Swearing at an agent just pollutes the context so I can’t even be afforded some catharsis.

If a senior SRE who had been burnt way too many times for reckless, unverified deployments asks for more qualitative and quantitative measurements of the efficacy of a newly pushed AI platform or tool, they are the heretics living in the past. Old school. Unimaginative. Getting in the way of innovation. They must be reformed into rethinking reliability as a negotiable attribute tolerant of stochastic outcomes. Incidents are a byproduct of necessary progress.
SLOs? Error budgets? Verify before deploy? Production Readiness Review (PRR)? A/B testing? Get that out of here. Use AI AI AI to speed up the output delivery. At the first sight of a mirage of productivity, cautious AI adoption gives way to adopt AI at all costs.
Everyone must no longer aspire to be T-shaped normies. The meta is now a horizontal, thick, fat I-shaped engineer. AI hath giveth thee all means to gain knowledge in any field, there’s no longer any excuse to not have adequate knowledge in everything and deliver output on all fronts.
Pragmatically, however, I think the realistic outcome has been Serrated-shape Engineers:
People with broad, spontaneous, mid-level understanding of a subject just enough to appear to get something done, but also just enough to accidentally cut themselves.
# Hot Take 4: Agentic SREs Will Not Save You
## Problem: Observability Data Unification
Recently I attended a tech conference where it was unsurprising to hear yet another thousand mentions of Artificial Intelligence. During the speaker panel session, the sentiments about running autonomous SRE agents to automate the triaging and mitigation varied between “we don’t really trust the output, but we consult” to “this is the best thing since agentic sliced bread”. In the latter camp, one of the panel speakers mentioned that he no longer believes that the unification of organisational telemetry ingestion is the solution to responsive triaging and mitigation.
In fact, he plans to skip right past data federation and jump straight to “federated agents” to solve this data access problem. I can empathise with this attempt at what is going to be an unfruitful endeavour.
My Thoughts
Given the enormous amount of heterogeneous workloads and tooling in a large organisation, demanding every single team to deploy an autoinstrumented OTel Collector is every SRE’s political nightmare. Some teams might use Stackdriver, some might use Cloudwatch. On-premise deployments may already be using Splunk, Dynatrace, LGTM stack, Clickstack or something else. Some teams might still be SSH-ing into VMs to look at /var/log with no understanding of metrics or traces. During incidents, the Incident Commander would have to rely entirely on the word of engineers within each team to figure out which rollout is causing the outage, and humans lie. Ideally, the SRE organisation would work out a multi-year deal with the CIO to enforce unification of telemetry, but this very rarely happens.
A common solution would be to carry out a Sisyphean push to onboard tenants to a central observability platform while negotiating requirements team by team. By the time 20% of the fleet is onboarded, the platform tooling is already obsolete. The obstacles are always workflow habits (dashboards and monitors), data migration, data classification, access policies, and pure inertia. Trying to sort this out team by team makes it incredibly MxN tedious. The only method that I have seen work out is to have the C-suite, either the CIO or CFO, mandate the data unification by a hard deadline. But I have never observed this done outside of Grab and Google. Even with this mandate, the Google P2020 team still met with so much resistance along the way.
Therefore the panel speaker declared that having expert agents in each data silo will be the solution to save them. Teams would no longer have to migrate their ingestion endpoints to a central OTel Collector, migrate their dashboards and monitors, or federate any data instances. Just run a MCP server on their observability instance and expose it to a data silo agent. All the silo agents would then report to an orchestrator master agent that would handle outage triage.
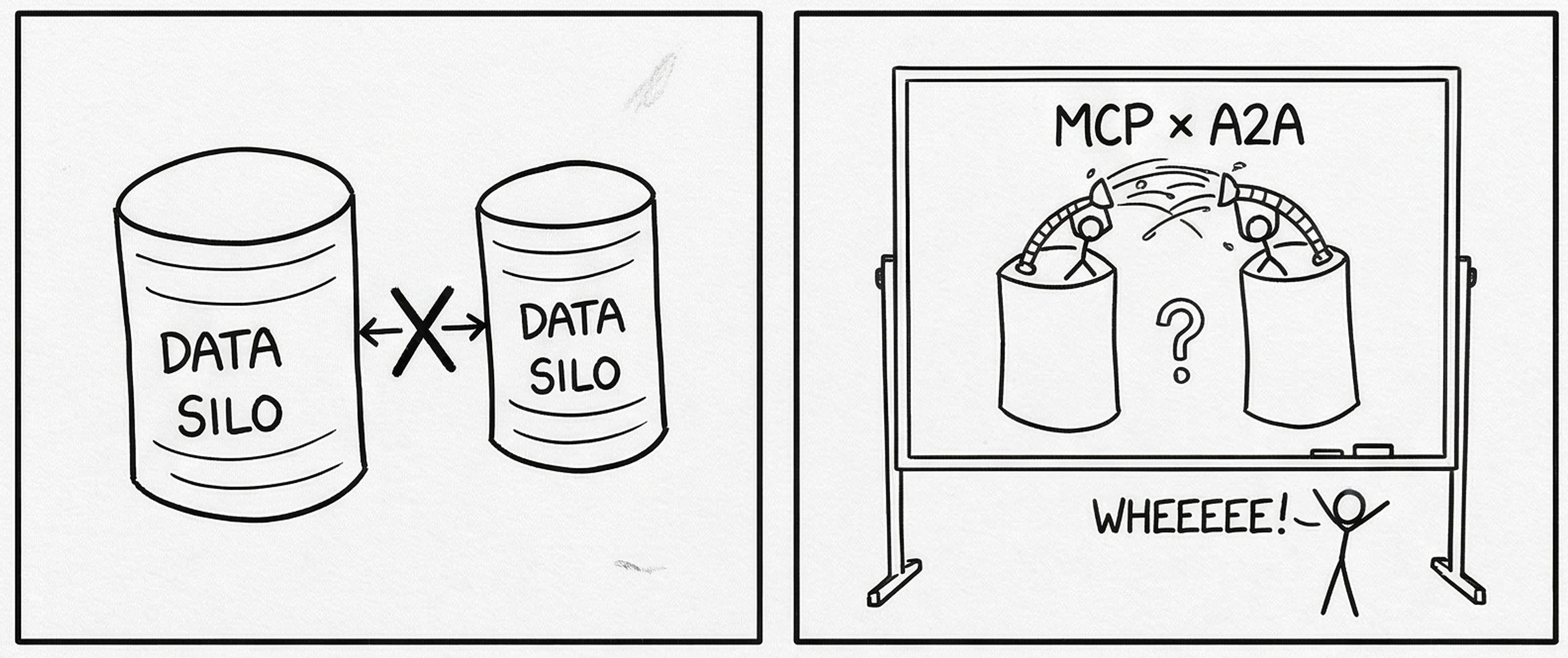
This sounds great on paper. But I must ask:
- If teams had refused to do simple data federation due to data policy concerns, why would they start extensively customising RBAC roles to host an all-access-buffet MCP server?
- If teams didn’t standardise due to a lack of telemetry instrumentation to begin with, why would they build a none-you-can-eat-buffet MCP server?
The only real value that LLMs would provide in such circumstances is the interpretation of different telemetry storage formats, but that isn’t the main problem is it? The main problem with triage and diagnostics has always been about data access, not the means of data access. Slapping a glorified JSON-RPC server on top is not going to magically solve this issue. If there is enough data access for an agent to function effectively, you likely don’t need an agent for 99% of your outages.
No one needs GPUs crunching CUDA cores to tell them that the rollout 5 minutes before the outage needs to be rolled back. Deterministic canary automation tools like Flagger has solved this eons ago in a far more compute efficient manner.
If… the data is already there.
## Problem: Agentic SRE Does Not Solve The Real Everyday Issues Of The Average Organisation
Are you working in a company with a highly opinionated tech stack coupled with mature documentation and observability? Congratulations! You can start experimenting with Agentic SRE.
But do look through the eyes of the everyday SWE. For the average tech organisation, the reality is that agentic SRE is not going to miraculously make outage triage and mitigation simpler anytime soon.
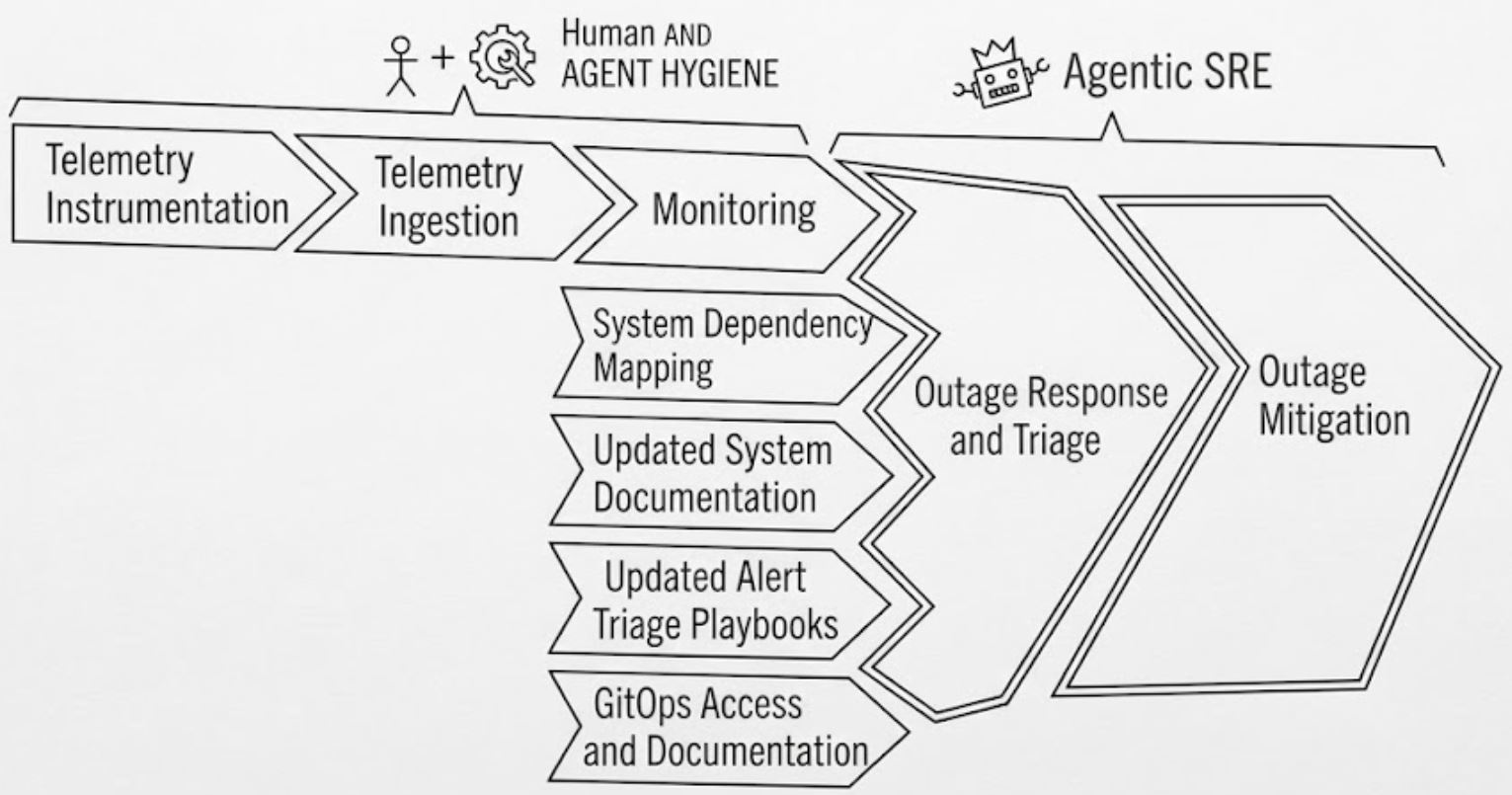
As highlighted in the first problem, system health aggregation is a data access problem. Many large organisations with critical legacy systems do not have a unified ingestion pipeline for telemetry and event logs. Some don’t even instrument telemetry in the first place. If system owners aren’t even capable of or incentivised to instrument telemetry, why would they bother with building a custom MCP server? And what would that MCP server serve? Raw syslogs that would choke the context window to death?
I find the idea of slapping MCP and A2A on top of lacking observability, both lazy and irresponsible. Not only would it yield terrible hallucinations with no context of system dependencies, it’s going to eat up so many tokens to crap out nothing of use. For an agentic SRE to attain just one 9 of usefulness, it needs the humans to:
- Instrument telemetry
- Ingest telemetry
- Monitor the telemetry
- Chart out a system dependency map that is live updated and suffers no drift
- Keep system documentation permanently updated
- Keep alert playbooks up to date
- Properly ACL GitOps access along with updated repository documentation
Any drift in the above human requirements would cause the agent to turn into a clown. Several segments of the toil work above could be automated with more agents, but it needs the careful implementation by the engineers to make it work.
Unless the companies pushing for higher AI adoption are willing to slow down its feature launch cycles by a year to treat the automation of context generation a product in its own right, no one is going to have the bandwidth nor patience to deal with that as a side hobby.
# Hot Take 5: AI Companies Peddling Coding Agents Don’t Believe In Their Own Products
This one is simple. There is a RAM shortage, people need more memory efficiency.
If AI coding companies truly think that their tools are the absolute shizzle, why is their commandline tool written in Javascript? What has everyone done to Google and Anthropic to deserve having to run a Node.js runtime for a terminal cli? Should everything not be written in Golang or Rust to be as lightweight as possible on the users’ machines? Why is the need to manage React components in the terminal even a thing? These tasks should be done with the most resource efficient language using their own peddled coding agents.
But the fact is that the developers for the exact same tools they are selling, don’t believe enough in it to write code that they trust. Despite telling everyone that all you need is proper agent orchestration with agentic roles for PM, EM, SWE, SRE, DevOps to work with each other crunching millions of tokens per hour, these companies don’t actually practise what they preach. If they did, you’d be running Claude Code developed in Golang.
I do have to say that the most optimum agentic coding language is Golang.
It’s simple, performant, memory efficient, portable, and vibe-coding friendly in the sense that the compile times are faster than Typescript’s Golang-powered transpile time. It does crunch more tokens than logic dense dynamic languages, but anecdotally hallucinates a lot less. I tried vibe coding with Rust but the LLVM compile time is way too painful for my high frequency 777 dopamine fix. Zig had far too many breaking changes between versions and suffers from the same LLVM compile times.
# Hot Take 6: The Moat For Enterprise Software Is Going To Be Documentation
Have you heard about the SaaSpocalypse proclaimed by various experts? These people are delusional.
Yes, one-trick tools have become a thing of the past, there is no doubt about that. Some stuff that I have created on a whim thus far:
- Slack emoji generator that converts a video into an animated GIF scaled down to 128x128 with appropriate downsampling on frames to fit 128KiB.
- Video/Image format converters
- Simple DNS just for fun
- Browser snipping tool to share screenshots
These things used to be passion projects by internet strangers. We would visit suspicious looking websites selling PDF2MSDoc.exe and pay money just to fix a file sharing issue. Now, I just tell Claude Code what I need and I get a half-hearted prototype that works just well enough.
Coding agents are like the Replicator in Star Trek: You can make anything you want, it just doesn’t taste as good.
Enterprise software, however, isn’t so much about providing a single feature you want. Companies buy enterprise support not solely for the premium feature sets, but also for the liability. When your vibe coded platform implodes in the middle of the night, who is going to be there to debug and fix the issue of what is essentially a brownbox slop fest? No, companies buy enterprise support so that they have domain experts to page when things go south. Companies buy enterprise support to ensure compliant system integrations spanning more than 1 context are carried out without a hitch.
Given that LLMs with RAG make searching through technical documentation far easier, a likely outcome for enterprise software is the gatekeeping of documentation. This is to prevent the common SWE from easily becoming a domain expert and replacing their value proposition. Forget about community OSS versions that people can easily fork and extend features using agents. Companies are now going to build new licensing models targeted at agentic cloning, or dig a closed source moat around all of their software while enshittifying the publicly available docs. Want our most updated documentation? Buy our technical support and you can read it through our specially crafted AI agent.
# Hot Take 7: AI Can’t Do Infrastructure
This was surprising to me.
I had assumed that declarative Infrastructure-as-Code would be one of the easiest things for coding agents to figure out. HCL and YAML manifests have barely any fancy logic to them, and are designed to be verbose while explicit. I assumed wrong.
While I am not quite certain of the reasons, I have a few guesses.
## The Lack of Logic Makes It Hard for Agents to Estimate the Intention
Even within the small context of spinning up a VPC and allocating CIDR ranges to several subnets, agents would generate syntactically correct manifests that don’t render the outcome requested. The developer would have to imbue meaning into each of the manifest clauses so that the NLP can interpret what needs to be done. But the training data on Github doesn’t provide the same context density that programming languages do (onStateUpdate has the meanings upon, state change of parent, callback whereas vpc main is just a main VPC), so it may be difficult for agents to correlate intent with outcome.
The inherent low density of context in IaC also means it is token inefficient as well. Integrating more than 2 subsystems may as well be solving a three-body problem for the limited context windows for LLMs.
## The Infrastructure Space is Full of Forks and Sprawling Providers that Do Similar Things

This is a recurring issue within the team I lead. The platform engineers that consult with LLM chatboxes or coding agents frequently find themselves sent down a rabbit hole into the abyss of hallucinations. Agents would regularly make up realistic sounding flag arguments and waste tokens retrying different permutations of the same non-existent, never existed flags. If you’re using forked tools like OpenBao and OpenTofu, it will invent cross-breed features that exist in neither the fork nor the parent about half the time. 80-90% of the time it confuses features between the fork and the source, quoting technical documentation that doesn’t exist.
If adopting IaC providers, agents would get bamboozled by different community providers doing similar functions because it somehow assumes all providers for the same infrastructure resource are one and the same. Another behaviour I would see is the agent attempting to use enterprise premium features and just give up when it fails. “Oh yeah I guess you have to pay now.”
Attempting to use agents to brute force the enterprise integrations is an exercise in futility when all of the technical documentation for enterprise specific features are locked behind a paywall, so the literature doesn’t exist in the model nor is it available for RAG.
## Lack of a Feedback Loop
While testing code is as easy as go test ./..., testing infrastructure costs a lot of money. Agentic infrastructure testing is both costly and extremely risky.
The responsible method is to create an isolated environment and give the agent restrictive access controls to test out its configurations in a loop. But we all know that by the 10th time the agent fails due to restrictive IAM policies, we’d probably be switching to Allow "*" in its own cloud account. And that could easily result in runaway bills that explode our budget.
One alternative I have tried is to run local machine Kubernetes clusters and just let the coding agents go nuts. I would swap in Opus 4.6, Sonnet 4.6, Gemini Pro 3.1 to test the results. After a week of 7-8 context compactions and millions of tokens, here’re the observations:
- They all failed to deliver anything beyond single cluster integrations and heavily preferred cli over Helm.
- They would beg to negotiate on the specifications. “I’m le tired. Why do multi-cluster when 1 cluster do trick?”
- They would give up after a while and say yeah okay there’s no way this can be done.
- Local Kubernetes clusters behave differently from production clusters so the output isn’t always usable.
- Infrastructure turn up time is slow, so most of the cycles are wasted on waiting.
- The goto method to debug their configurations is always to nuke all of the clusters and rebuild from scratch.

I believe that infrastructure has one extra layer of isolation and delay between the agent’s actions and actuation that’s causing the agents to struggle. Perhaps the AI companies would like to release more targeted models for the IaC crowd in future.
# End of Ramble

So that about sums up my AI hot takes. In the meantime, I advise people who are absolutely peeved about the mass of AI shovelware to just tune it out and use what works for you. If anyone preaches about adopting more AI, ask them for a practical demo before buying into the sales pitch. Talk and build are easy, real-world day-2 maintenance is hard.