It's common to use random UUIDs as a primary key in databases. One of the known downsides of random UUIDs is that their unordered nature (UUID4) can cause a lot of extra paging for the clustered index because you are inserting rows randomly into the Btree and having to re-balance it. This post tries to help us develop a more visceral understanding of the performance cost of all that extra paging.
While this post is about SQLite specifically, the problem of random UUIDs also extends to other databases that use clustered indexes.
What is a clustered index?
A clustered index determines the physical storage order of the rows in a table. Because of this:
- There can be only one clustered index per table (rows can only be physically sorted one way).
- A clustered index is the table.
- A non-clustered index, by contrast, stores only the indexed columns plus a pointer to the actual row data, which lives elsewhere.
Rowid
Every ordinary SQLite table has an implicit 64-bit integer primary key called rowid. The table's data is stored in a B-tree structure containing one entry for each table row, using the rowid value as the key. This is effectively SQLite's clustered index. The physical storage order of rows follows rowid sequence.
Without rowid
SQLite also supports WITHOUT ROWID tables. These tables have no implicit rowid. Instead, the primary key you declare becomes the clustered index.
Note: In SQLite rowid tables are implemented as B-Trees where all content is stored in the leaves of the tree, whereas WITHOUT ROWID tables are implemented using ordinary B-Trees with content stored on both leaves and intermediate nodes.*
Baseline
Let's establish a performance baseline with regular rowid int primary key. We'll insert 10 million rows in batches of 1 million.
(d/q writer
["CREATE TABLE IF NOT EXISTS event(id INTEGER PRIMARY KEY, data BLOB)"])
(dotimes [_ 10]
(time
(d/with-write-tx [db writer]
(dotimes [_ 1000000]
(d/q db ["INSERT INTO event (data) values (?)" data])))))
Results:
| total rows | time in ms |
|---|---|
| 10000000 | 838 |
| 20000000 | 762 |
| 30000000 | 819 |
| 40000000 | 713 |
| 50000000 | 721 |
| 60000000 | 757 |
| 70000000 | 692 |
| 80000000 | 702 |
| 90000000 | 696 |
| 100000000 | 715 |
Roughly a million inserts per second.
UUID4 WITHOUT ROW ID
Now lets try UUID4.
(d/q writer
["CREATE TABLE IF NOT EXISTS event(id BLOB PRIMARY KEY, data BLOB) WITHOUT ROWID"])
(dotimes [_ 10]
(time
(d/with-write-tx [db writer]
(dotimes [_ 1000000]
(d/q db ["INSERT INTO event (id, data) values (?, ?)"
(random-uuid4-bytes) data])))))
Results:
| total rows | time in ms |
|---|---|
| 10000000 | 2649 |
| 20000000 | 5644 |
| 30000000 | 7137 |
| 40000000 | 8352 |
| 50000000 | 9359 |
| 60000000 | 9817 |
| 70000000 | 10490 |
| 80000000 | 11130 |
| 90000000 | 11668 |
| 100000000 | 12586 |
Oh no! What's happened here the inserts are 14-16x slower?!
Profile
That's a big difference. But, lets not guess when we can profile.
Below is a normalised diffgraph. A diffgraph compares two profiling snapshots (in this case INTEGER vs UUID4) and displays the differences in a flamegraph structure. Unlike a regular diffgraph that shows absolute changes, a normalised view adjusts the total number of samples between the two compared profiles to be the same. This means we can see the relative differences as a percentage. This matters because our profiles will run for different amounts of time.
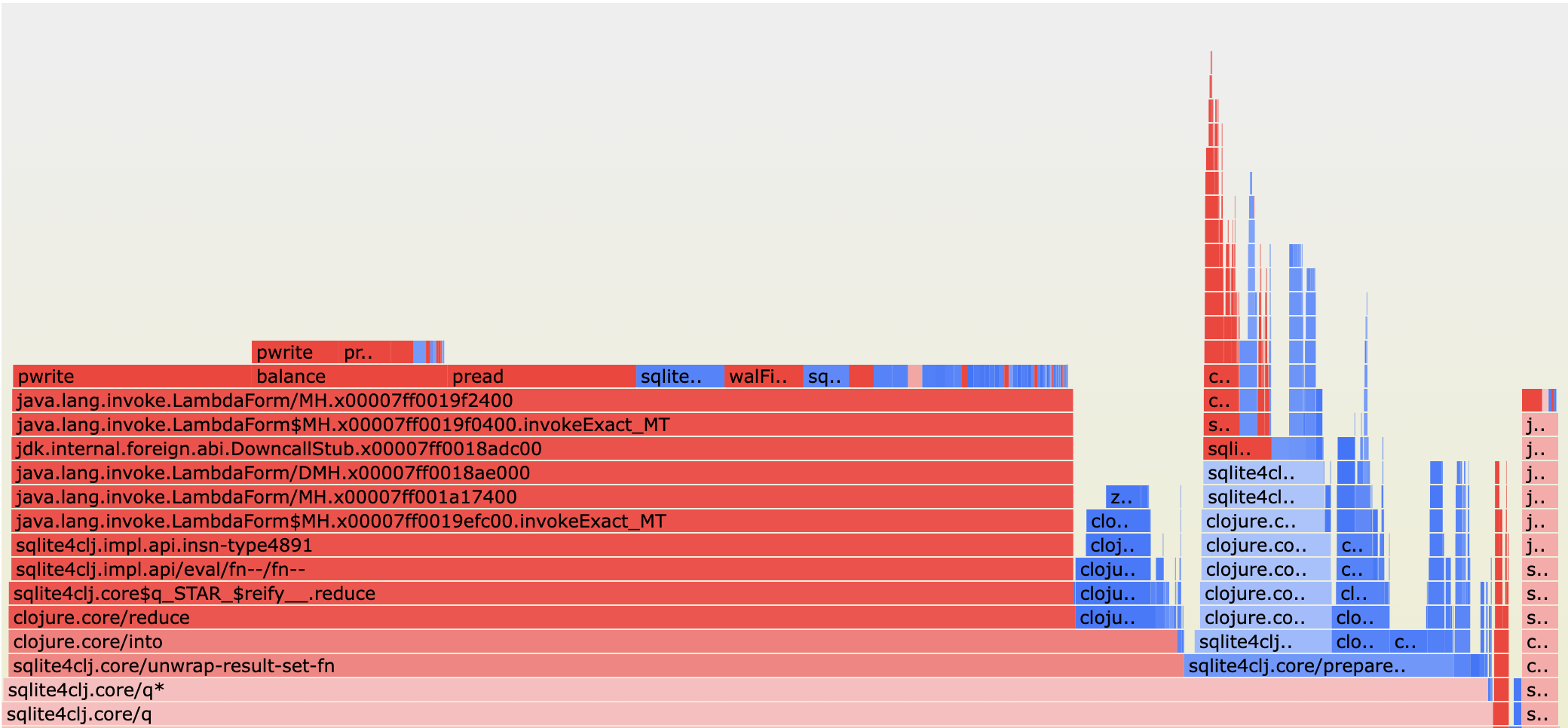
The colour signifies the direction of the change: a blue frame means less time was spent in this function in the second profile (UUID4) compared to the first (INTEGER); a red frame means more time was spent in the second profile. The colour intensity indicates the relative change in the number of samples for the frame itself (self time delta).
We can see from the diffgraph that we are spending a lot more time balancing the tree, reading and writing. This is because the unordered nature of UUID4 means they are ordered randomly which is forcing SQLite to constantly re-balance the Btree.
UUID7 WITHOUT ROWID
We can theoretically fix this with UUID7 which is time ordered eliminating the ordering problem of UUID4. Let's see if this improves things.
(d/q writer
["CREATE TABLE IF NOT EXISTS event(id BLOB PRIMARY KEY, data BLOB) WITHOUT ROWID"])
(dotimes [_ 10]
(time
(d/with-write-tx [db writer]
(dotimes [_ 1000000]
(d/q db ["INSERT INTO event (id, data) values (?, ?)"
(random-uuid7-bytes) data])))))
Results:
| total rows | time in ms |
|---|---|
| 10000000 | 1372 |
| 20000000 | 1280 |
| 30000000 | 1365 |
| 40000000 | 1250 |
| 50000000 | 1256 |
| 60000000 | 1270 |
| 70000000 | 1246 |
| 80000000 | 1257 |
| 90000000 | 1245 |
| 100000000 | 1258 |
Back to a more reasonable number. Still slower than our baseline. UUID blob primary keys are 16 bytes vs int primary keys which are 8 bytes.
UUID4 WITH ROWID
Now lets try UUID4 WITH ROWID. This means the hidden rowid will be the clustered index. The upside of this is rowid is sequential. The downside is that the table now has two indexes so there will be write amplification.
(d/q writer
["CREATE TABLE IF NOT EXISTS event(id BLOB PRIMARY KEY, data BLOB)"])
(dotimes [_ 10]
(time
(d/with-write-tx [db writer]
(dotimes [_ 1000000]
(d/q db ["INSERT INTO event (id, data) values (?, ?)"
(random-uuid4-bytes) data])))))
Results:
| total rows | time in ms |
|---|---|
| 10000000 | 2003 |
| 20000000 | 2324 |
| 30000000 | 3285 |
| 40000000 | 4399 |
| 50000000 | 5194 |
| 60000000 | 5659 |
| 70000000 | 6215 |
| 80000000 | 6467 |
| 90000000 | 6924 |
| 100000000 | 7119 |
This doesn't perform as well as UUID7 WITHOUT ROWID partly because you still building an index with random insertions (even though it's not the clustered index).
Conclusion
Hopefully, this post helps illustrate some of the pitfalls with UUID primary keys in SQLite and how to navigate them.
The full benchmark code can be found here.
If you enjoyed this post you might like this one 100000 TPS with SQLite
Further reading
- Clustered Indexes
- Clustered Indexes and the WITHOUT ROWID Optimization
- clj-async-profiler
- Exploring flamegraphs
- Diffgraphs
Thanks to Everyone on the Datastar discord who read drafts of this and gave me feedback.