Don't Roll Your Own …
By Susam Pal on 23 May 2026
This is going to be a rant about modern web design practices. But before I get to that, let me begin with a familiar principle from the world of cryptography. Among software developers, and especially among those who work on security-sensitive systems, there is a well-known maxim: Don't roll your own crypto. This does not mean that nobody is allowed to write cryptographic code. Someone has to. It means that, for ordinary production software that protects sensitive data of users, you should not rely on a private, unreviewed implementation that only you and your team have looked at. You should use established, vetted software packages or tools wherever possible.
Fortunately, it is now standard industry practice to avoid rolling your own crypto and instead use cryptographic algorithms and packages that have been peer reviewed and stood the test of time. It wasn't so some twenty years ago. I have seen several flawed home-grown RC4 implementations early in my career, with issues like improper initialisation vectors, predictable keystreams and partial leakage of plaintext into ciphertext, putting sensitive data of users at risk. But today, no major e-commerce site or bank uses home-grown cryptography for its web services. In fact, in regulated domains such as payments, healthcare, government systems and personal data processing, doing so could violate requirements for strong cryptography, possibly leading to hefty financial penalties.
Website design is obviously not cryptography. A broken scroll bar is not the same kind of failure as a broken encryption scheme. But I wish there were a similar maxim for website design as well. There are many aspects of websites where, I think, developers should not be rolling their own X, especially when X is something browsers already do well and something users depend on every day. Here I present a list of such X.
- Don't roll your own page scrolling.
- Don't roll your own link navigation.
- Don't roll your own text selection.
- Don't roll your own context menu.
- Don't roll your own copy and paste.
- Don't roll your own password field.
- Don't roll your own date picker.
The one that bothers me the most is custom scroll behaviour on websites. I am used to how page scrolling responds to my mouse, touchpad or keyboard input. When you override the default scrolling behaviour of the web browser with your own implementation, it 'breaks' the page for me. The page now moves too slowly or too quickly when I scroll. Keyboard scrolling may or may not work. You take something I am so familiar with that I don't even think about it, and turn it into something unfamiliar that I now have to think about.
Custom link navigation is another pet peeve of mine. Web browsers can already handle links very well. You could say that this is the whole reason web browsers even exist. Following links is their bread and butter. You shouldn't have to mess with that behaviour at all. If you think you need to, reconsider what you are trying to achieve and whether it is really so important as to disrupt normal link navigation. The worst offender I have found here is GitHub. When you click on a link on GitHub, say, a file link or an issue link, it triggers a massive piece of functionality implemented in JavaScript that handles the link click for you. If you don't believe me, visit your favourite project on GitHub using Firefox or Chrome, type F12 to open the browser's developer tools, then go to the 'Debugger' or 'Sources' tab, find 'Event Listener Breakpoints' on the left sidebar, expand 'Mouse' and select 'click'. Then click on a link on GitHub and see what happens.
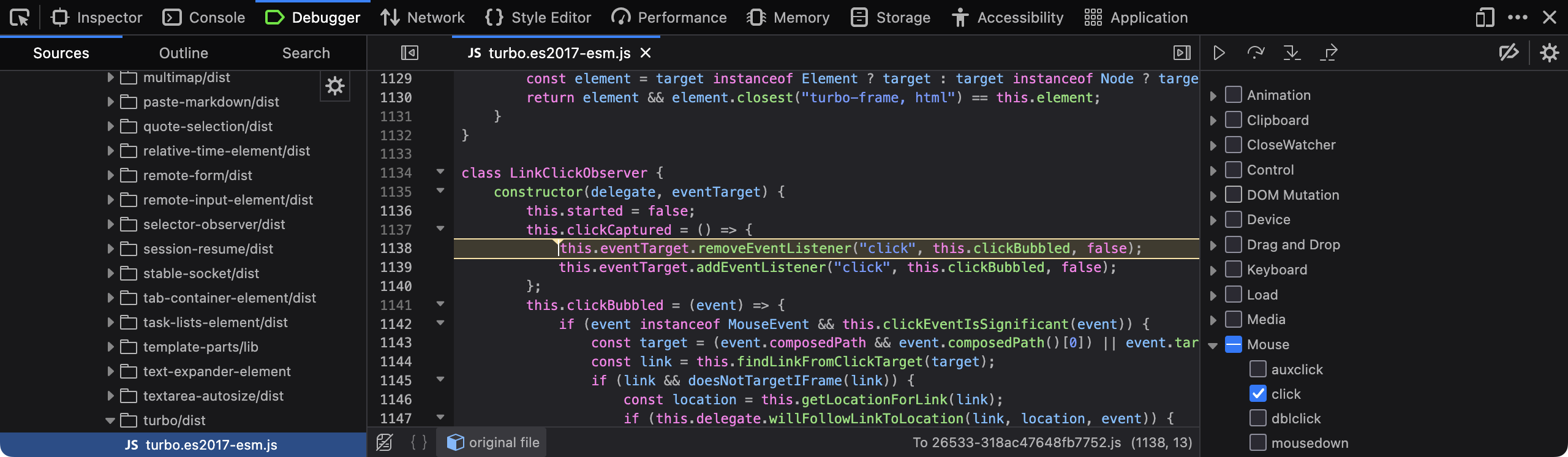
I'm sure I am not the only one who has noticed that, on GitHub, a clicked link sometimes takes too long to load. Ironically, it is often faster to open the link in a new tab than to wait for GitHub's JavaScript code to handle the navigation in the current tab.
A custom password input field is another such hazard. Fortunately, custom password input fields have become rarer over the years. The password input field that comes with the web browser is generally well equipped to handle passwords. It can offer to save passwords, fill them in later and generate strong passwords for new accounts. It can also warn when a password is submitted over an insecure HTTP connection, work well with password managers and autofill, and cooperate with mobile keyboards and accessibility tools. If you replace the browser's password field with your own fake version, you may break all of that. You may also end up using an ordinary text field and masking it yourself, in which case the password may be treated by the browser, the operating system or assistive tools as ordinary visible text rather than as a password, thereby exposing the password in ways you did not intend.
Custom date pickers are another common annoyance. I know that
<input type="date"> does not help you select a
date range. But that is okay. You can provide two date input
fields, one for the start date and one for the end date. I am
willing to pay the small price of using two different inputs to
select a date range if that means I can use dates the same way
everywhere. What I am not willing to do is learn ten different ways
of using the date selector in ten different implementations across
ten different websites. I already know how the date picker in my
web browser works, and I want to use that.
In general, just stop rolling your own form controls. They almost always introduce new problems while solving some existing ones. And while you are at it, don't keep changing your website layout and interface every few months! I may adapt to the new design, but my ageing relatives cannot. For them, every time you change the user interface, it amounts to learning a whole new tool. Imagine how you would feel if a Linux distribution decided to redesign all its core commands and their command-line options every few months. Or imagine how you would feel if the buttons of your washing machine were rearranged every morning. It wouldn't be pleasant!